SQL模糊查询不要总是用 LIKE ''s%''
|
admin 2024年12月12日 9:10
本文热度 2029
2024年12月12日 9:10
本文热度 2029
|
在数据库查询中,模糊查询是一个非常常见的需求,特别是在处理大量数据时。许多开发者在使用Oracle数据库时,经常习惯性地使用 LIKE 's%' 来实现模糊查询,以获取以特定字母开头的数据。你想过 LIKE 被大多数场景使用,这可能会有什么问题吗? 首先,虽然 LIKE 的确能满足基本的模糊匹配需求,但它并不是万能的。在某些情况下,过度依赖 LIKE 可能会导致性能问题。比如,当表中数据量非常庞大时,使用 LIKE 进行模糊查询可能会导致全表扫描,这样不仅耗时,还会增加数据库的负担。 其次,LIKE 的使用逻辑并不总是清晰。很多时候,我们可能想要的不仅仅是以某个字符开头的数据,而是包含特定字符或者符合其他更复杂的条件。这时候,单纯的 LIKE 's%' 就显得有些力不从心了。比如,如果你想找到所有包含字母“s”的记录,使用 LIKE 就无法实现了,而这时使用正则表达式(REGEXP)会更加灵活和高效。 再者,使用 LIKE 可能会让查询的意图不够明确。我们在编写 SQL 查询时,应该尽量让查询逻辑清晰易懂。如果只是一味地使用 LIKE,可能会导致代码可读性降低,其他开发者在维护时就会感到困惑。 那么,如何才能在模糊查询中更好地表达我们的意图呢?首先,建议结合其他条件进行查询。例如,如果我们想要找到所有以“s”开头并且年龄大于30岁的员工,可以这样写:SELECT * FROM employeesWHERE name LIKE 's%' AND age>30;
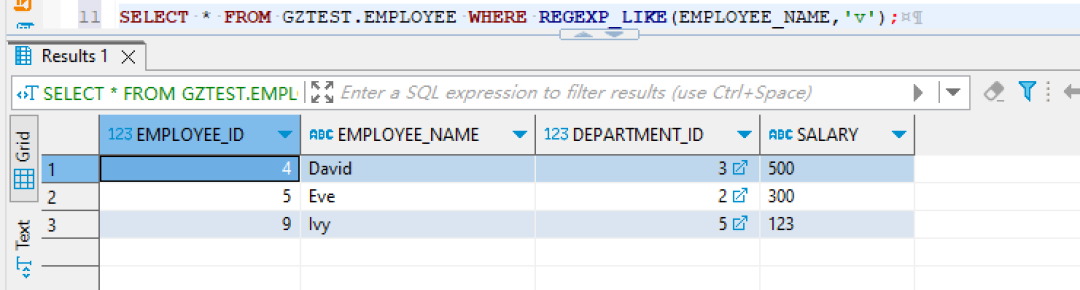
这样的查询不仅能够提高查询的精确度,还能提升性能。 另外,考虑使用正则表达式也是一个不错的选择。Oracle支持的 REGEXP_LIKE 函数可以让我们进行更复杂的模式匹配。例如,查找所有包含字母“s”的名字,可以这样写:SELECT * FROM employees WHERE REGEXP_LIKE(name,'s');
模糊查询是数据库操作中不可或缺的一部分,但Like绝对不是唯一的方式,我们不能仅仅依赖于 LIKE。在实际开发中,合理选择查询方式,清晰表达查询意图,才能真正提升数据库查询的效率和效果。 REGEXP_LIKE 函数在处理复杂或灵活的字符串匹配时,相对于简单的 LIKE 操作符,提供了更加强大和灵活的方式。它不仅提升了代码的可读性和维护性,还能有效满足复杂查询的需求。在实际开发中,合理选择使用 LIKE 和 REGEXP_LIKE 可以帮助开发者编写出更高效、更清晰的代码。简单的来说,简洁用like,复杂的业务用 REGEXP_LIKE,因为它更加灵活。
该文章在 2024/12/12 10:32:15 编辑过






 400 186 1886
400 186 1886