CPU原子操作
原子操作,指一段逻辑要么全部成功,要么全部失败。概念上类似数据库事务(Transaction).
CPU能够保证单条汇编的原子性,但不保证多条汇编的原子性
那么在这种情况下,那么CPU如何保证原子性呢?CPU本身也有锁机制,从而实现原子操作
眼见为实
int location = 10;
location++;
Interlocked.Increment(ref location);

常规代码不保证原子性

使用Interlocked类,底层使用CPU锁来保证原子性
CPU lock前缀保证了操作同一内存地址的指令不能在多个逻辑核心上同时执行
8byte数据在32位架构的尴尬
思考一个问题,x86架构(注意不是x86-64)的位宽是32位,寄存器一次性最多只能读取4byte数据,那么面对long类型的数据,它能否保证原子性呢?

可以看到,x86架构面对8byte数据,分为了两步走,首先将低8位FFFFFFFF赋值给exa寄存器,再将高8位的7FFFFFFF赋值给edx寄存器。最后再拼接起来。而面对4byte的int,则一步到位。
前面说到,多条汇编CPU不保证原子性,因此当x86架构面对超过4byte的数据不保证原子性。
如何解决?
要解决此类尴尬情况,要么使用64位架构,要么利用CPU的锁机制来保证原子性。
C#中的Interlocked.Read为了解决long类型的尴尬而生,是一个利用CPU锁很好的例子
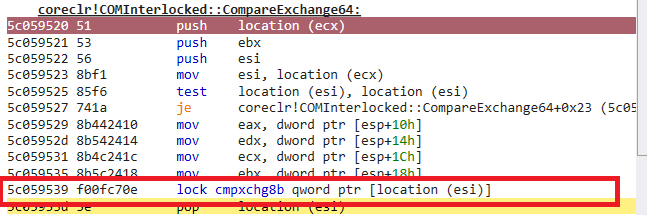
用户态锁
操作系统中锁分为两种,用户态锁(user-mode)和内核态锁(kernel-mode)。
优点:
通常性能较高,因为不需要进行用户态与内核态的切换,避免了切换带来的额外开销,如上下文保存与恢复等。例如在无竞争的情况下,用户态的自旋锁和互斥锁都可以快速地获取和释放锁,执行时间相对较短.
缺点:
在高并发竞争激烈的情况下,如果线程长时间获取不到锁,自旋锁会导致 CPU 空转浪费资源,而互斥锁的等待队列管理等也会在用户态消耗一定的 CPU 时间.
Volatile
在 C# 中,volatile是一个关键字,用于修饰字段。它告诉编译器和运行时环境,被修饰的字段可能会被多个线程同时访问,并且这些访问可能是异步的。这意味着编译器不能对该字段进行某些优化,以确保在多线程环境下能够正确地读取和写入这个字段的值
static class StrangeBehavior
{
private static bool s_stopWorker = false;
public static void Run()
{
Thread t = new Thread(Worker);
t.Start();
Thread.Sleep(5000);
s_stopWorker = true;
}
private static void Worker()
{
int x = 0;
while (!s_stopWorker)
{
x++;
}
Console.WriteLine($"worker:stopped when x={x}");
}
}
JIT编译优化的时候,发现while (!s_stopWorker)中的s_stopWorker在该方法中永远不会变。因此就自作主张直接生成了while(ture)来“优化”代码
class MyClass{
private int _myField;
public void MyMethod()
{
_myField = 5;
int localVar = _myField;
}
}
编译器认为_myField被赋值5后,不会被其它线程改变。所有它会_myFieId的值直接加载到寄存器中,而后续使用localVar时,直接从寄存器读取(CPU缓存),而不是再次从内存中读取。这种优化在单线程中是没有问题的,但在多线程环境下,会存在问题。
因此我们需要在变量前,加volatile关键字。来告诉编译器不要优化。
自旋锁
使用Interlocked实现一个最简单的自旋锁
public struct SpinLockSmiple
{
private int _useNum = 0;
public SpinLockSmiple()
{
}
public void Enter()
{
while (true)
{
if (Interlocked.Exchange(ref _useNum, 1) == 0)
return;
}
}
public void Exit()
{
Interlocked.Exchange(ref _useNum, 0);
}
}
使用Thread.SpinWait优化
上面的自旋锁有一个很大问题,就是CPU会全力运算。使用CPU最大的性能。
实际上,当我们没有获取到锁的时候,完全可以让CPU“偷懒”一下
public struct SpinLockSmiple
{
private int _useNum = 0;
public SpinLockSmiple()
{
}
public void Enter()
{
while (true)
{
if (Interlocked.Exchange(ref _useNum, 1) == 0)
return;
Thread.SpinWait(10);;
}
}
public void Exit()
{
Interlocked.Exchange(ref _useNum, 0);
}
}
SpinWait函数在x86平台上会调用pause指令,pause指令实现一个很短的延迟空等待操作,这个指令的执行时间大概是10+个 CPU时钟周期。让CPU跑得慢一点。
使用SpinWait优化
Thread.SpinWait本质上是让CPU偷懒跑得慢一点,最多降低点功耗。并没有让出CPU时间片,所以治标不治本
因此可以使用SpinWait来进一步优化。
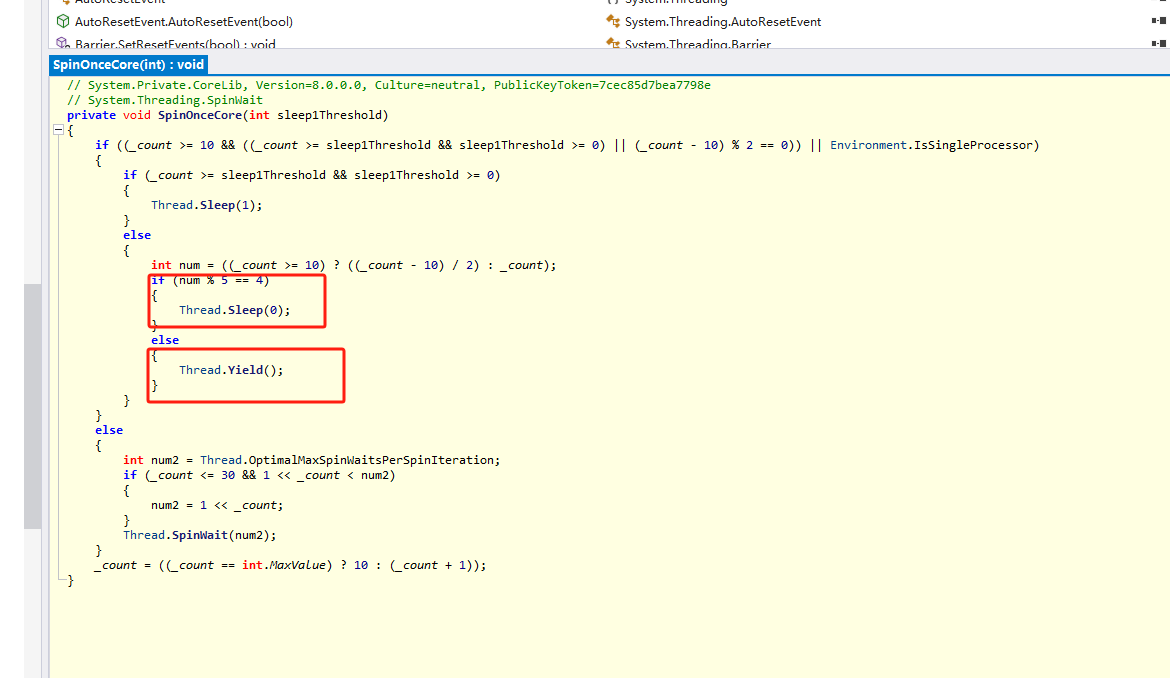
可以看到,在合适的情况下。SpinWait会让出当前时间片,以此提高执行效率。比Thread.SpinWait占着资源啥也不做强不少
使用SpinLock代替
SpinLock是C#提供的一种自旋锁,封装了管理锁状态和SpinWait.SpinOnce方法的逻辑,虽然做的事情相同,但是代码更健壮也更容易理解
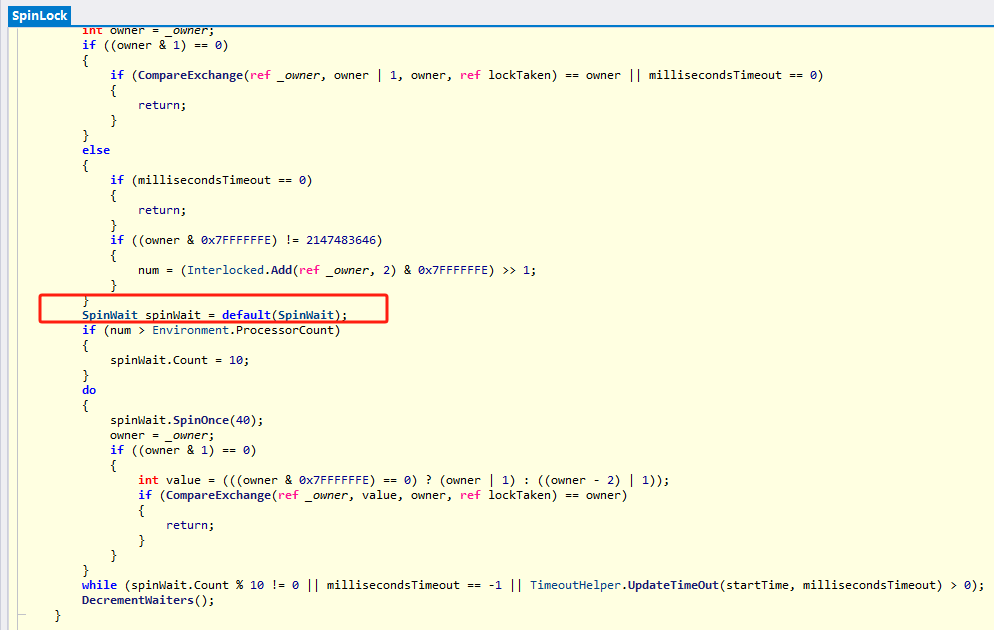
其底层还是使用的SpinWait
内核态锁
优点:
内核态锁由操作系统内核管理和调度,当锁被释放时,内核可以及时地唤醒等待的线程,适用于复杂的同步场景和长时间等待的情况.
缺点:
由于涉及到用户态与内核态的切换,开销较大,这在锁的竞争不激烈或者临界区执行时间较短时,会对性能产生较大的影响
事件(ManualResetEvent/AutoResetEvent)与信号量(Semaphores)是Windows内核中两种基元线程同步锁,其它内核锁都是在它们基础上的封装
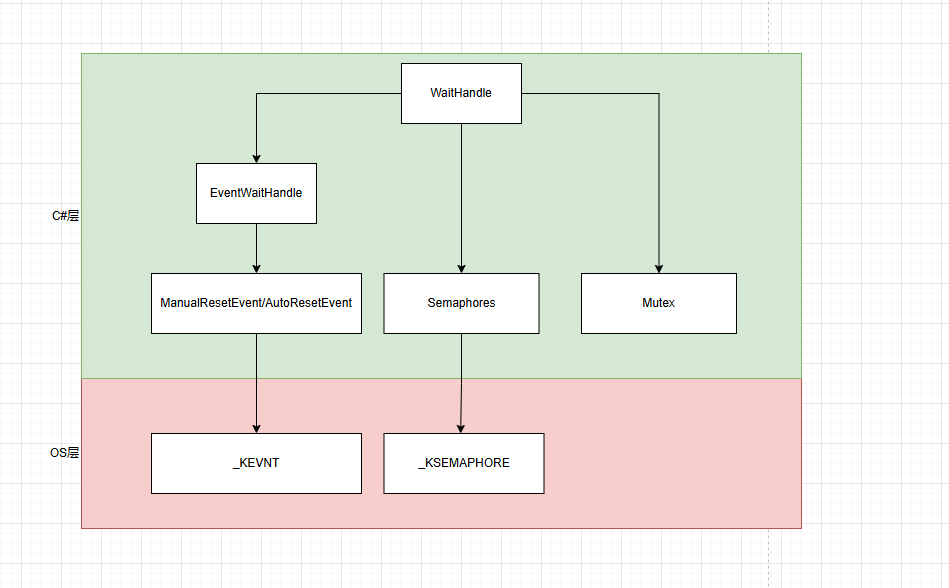
Event锁
Event锁有两种,分为ManualResetEvent\AutoResetEvent 。本质上是由内核维护的Int64变量当作bool来使,标识0/1两种状态,再根据状态决定线程等待与否。
需要注意的是,等待不是原地自旋,并不会浪费CPU性能。而是会放入CPU _KPRCB结构的WaitListHead链表中,不执行任何操作。等待系统唤醒
线程进入等待状态与唤醒可能会花费毫秒级,与自旋的纳秒相比,时间非常长。所以适合锁竞争非常激烈的场景
眼见为实:是否调用了win32 API(进入内核态)?
在Windows上Event对象通过CreateEventEx函数来创建,状态变化使用Win32 API ResetEvent/SetEvent
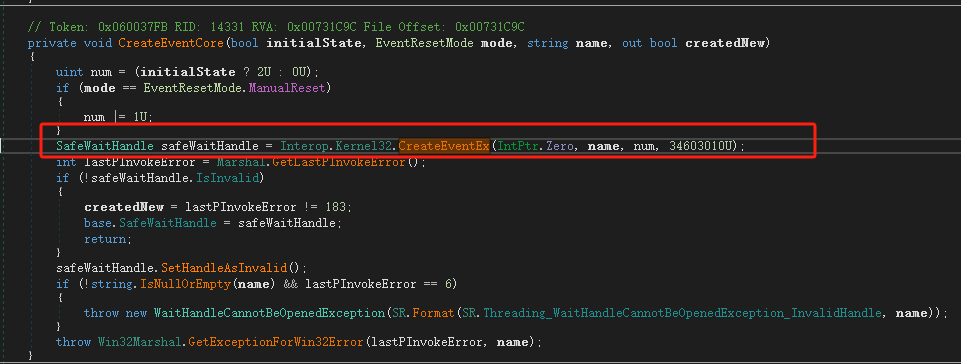
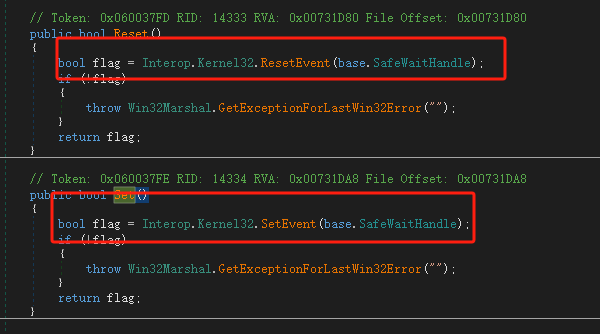
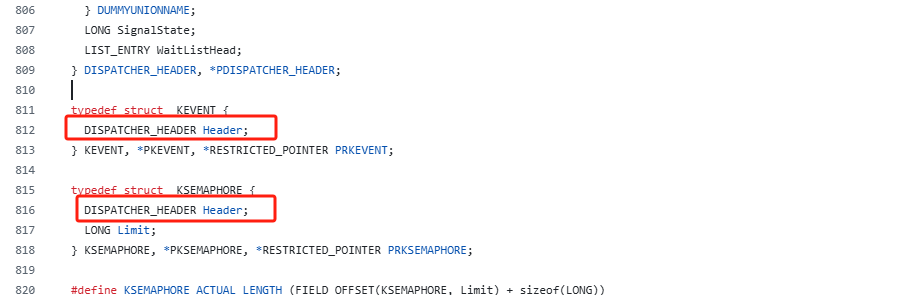
眼见为实:内核态中是否真的有long变量来维护状态?
https://github.com/reactos/reactos/blob/master/sdk/include/xdk/ketypes.h
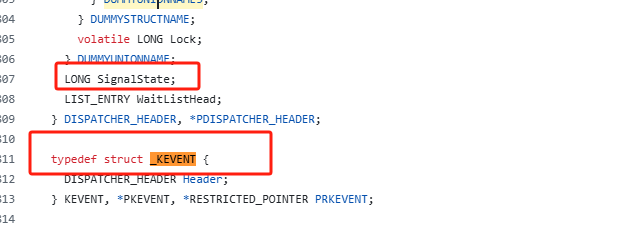
底层使用SignalState来存储状态
Semaphore锁
Semaphore的本质是由内核维护的Int64变量,信号量为0时,线程等待。信号量大于0时,解除等待。
它相对Event锁来说,比较特殊点是内部使用一个int64来记录数量(limit),举个例子,Event锁管理的是一把椅子是否被坐下,表状态。而Semaphore管理的是100把椅子中,有多少坐下,有多少没坐下,表临界点。拥有更多的灵活性。
眼见为实:是否调用了win32 API(进入内核态)?
在Windows上信号量对象通过CreateSemaphoreEx函数来创建,增加信号量使用ReleaseSemaphore,减少信号量使用WaitForMultipleObject
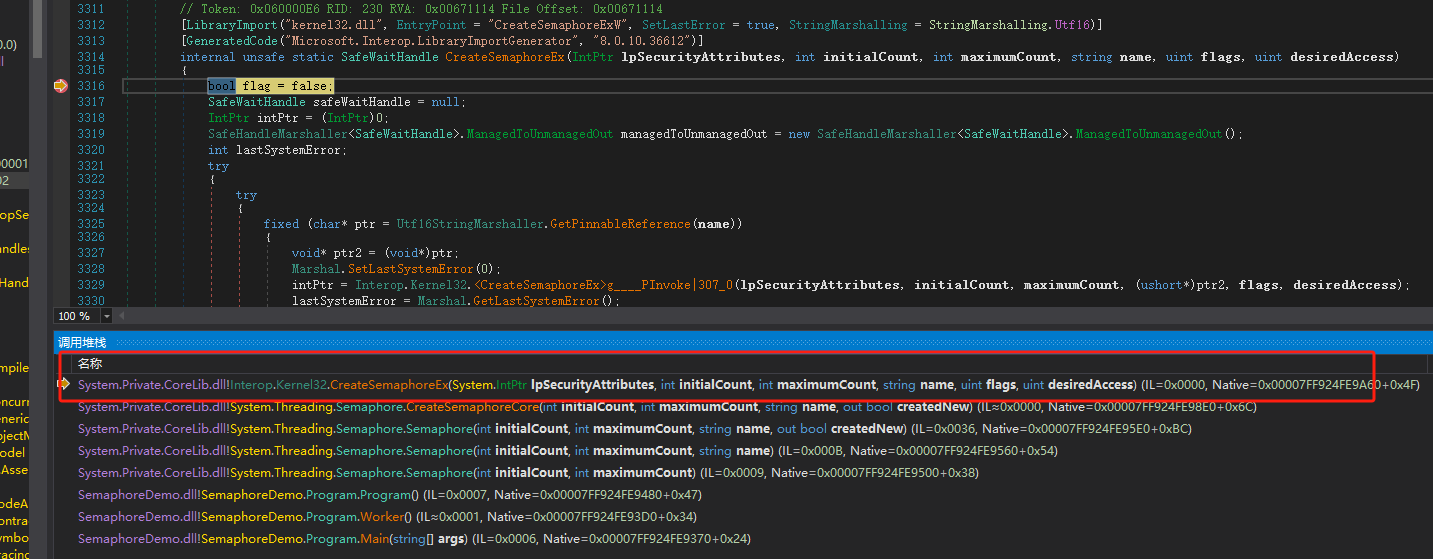
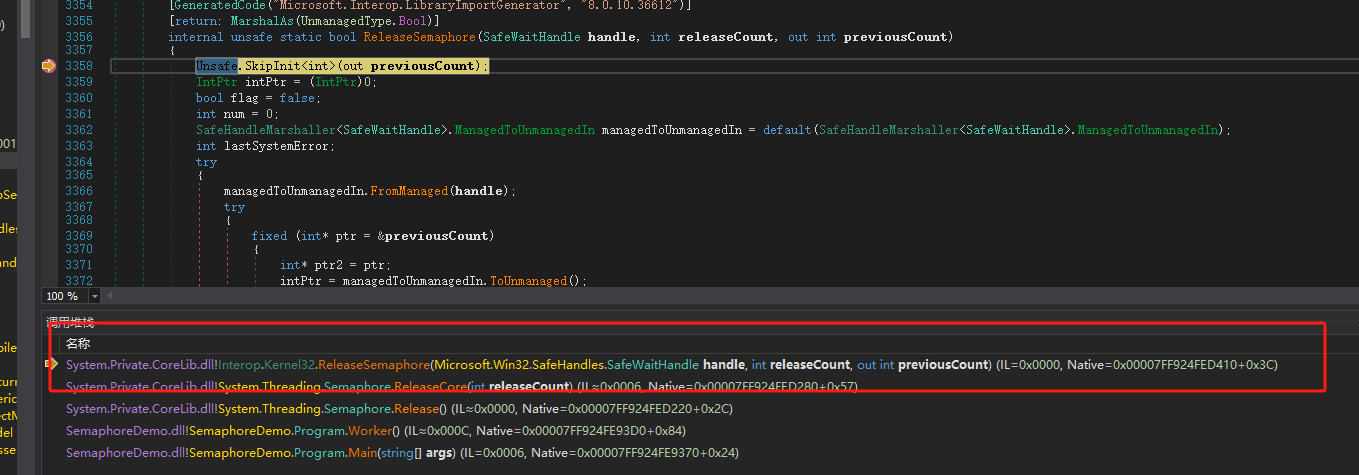
眼见为实:内核态中是否真的有long变量来维护状态?
参考Event锁,它们内部共享同一个结构
Mutex锁
Mutex是Event与Semaphore的封装,不做过多解读。
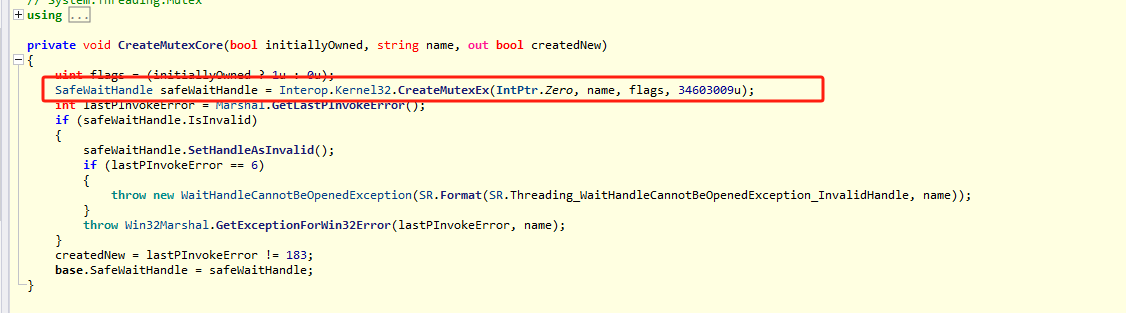
眼见为实:是否调用了win32 API(进入内核态)?
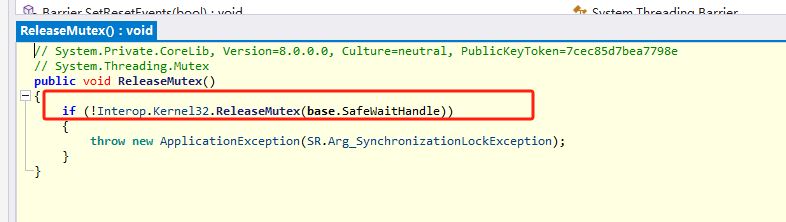
在Windows上,互斥锁通过CreateMutexEx函数来创建,获取锁用WaitForMultipleObjectsEx,释放锁用ReleaseMutex

混合锁
用户态锁有它的好,内核锁有它的好。把两者合二为一有没有搞头呢?

混合锁是一种结合了自旋锁和内核锁的锁机制,在不同的情况下使用不同策略,明显是一种更好的类型。
Lock
Lock是一个非常经典且常用的混合锁,其内部由两部分构成,也分别对应不同场景下的用户态与内核态实现
自旋锁(Thinlock):CoreCLR中别名瘦锁
内核锁(AwareLock):CoreClr中别名AwareLock,其底层是AutoResetEvent实现
Lock锁先使用用户态锁自旋一定次数,如果获取不到锁。再转换成内核态锁。从而降低CPU消耗。
Lock锁原理
Lock锁的原理是在对象的ObjectHeader上存放一个线程Id,当其它锁要获取这个对象的锁时,看一下有没有存放线程Id,如果有值,说明还被其他锁持有,那么当前线程则会短暂性自旋,如果在自旋期间能够拿到锁,那么锁的性能将会非常高。如果自旋一定次数后,没有拿到锁,锁就会退化为内核锁。
现在你理解了,为什么lock一定要锁一个引用类型吧?
点击查看代码
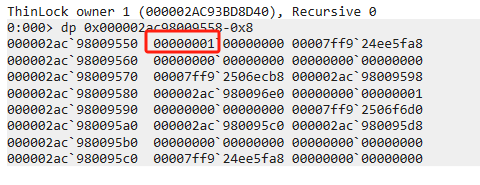
眼见为实:在自旋失败后,退化为内核锁
点击查看代码
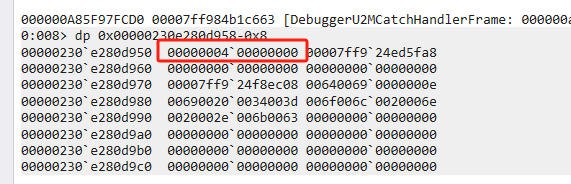
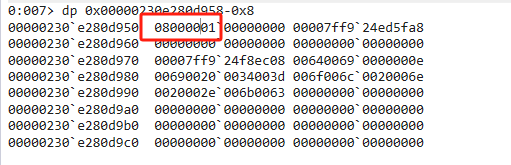
首先自旋,然后自旋失败,转成内核锁,并用SyncBlock 来维护锁相关的统计信息,01代表SyncBlock的Index,08是一个常量,代表内核锁

其它混合锁
基本上以Slim结尾的锁,都是混合锁。都是先自旋一定次数,再进入内核态。
比如ReaderWriterSlim,SemaphoreSlim,ManualResetEventSlim.
异步锁
在C#中,SemaphoreSlim可以在一定程度上用于异步场景。它可以限制同时访问某个资源的异步操作的数量。例如,在一个异步的 Web 请求处理场景中,可以使用SemaphoreSlim来控制同时处理请求的数量。然而,它并不能完全替代真正的异步锁,因为它主要是控制并发访问的数量,而不是像传统锁那样提供互斥访问
Nito.AsyncEx 介绍
https://github.com/StephenCleary/AsyncEx
大神维护了的一个异步锁的开源库,它将同步版的锁结构都做了一份异步版,弥补了.NET框架中的对异步锁支持不足的遗憾
无锁算法
即使是最快的锁,也数倍慢于没有锁的代码,因从CAS无锁算法应运而生。
无锁算法大量依赖原子操作,如比较并交换(CAS,Compare - And - Swap)、加载链接 / 存储条件(LL/SC,Load - Linked/Store - Conditional)等。以 CAS 为例,它是一种原子操作,用于比较一个内存位置的值与预期值,如果相同,就将该位置的值更新为新的值。
举个例子
internal class Program{
public static DualCounter Counter = new DualCounter(0, 0);
static void Main(string[] args)
{
Task.Run(IncrementCounters);
Task.Run(IncrementCounters);
Task.Run(IncrementCounters);
Console.ReadLine();
}
public static DualCounter Increment(ref DualCounter counter)
{
DualCounter oldValue, newValue;
do
{
oldValue = counter;
newValue = new DualCounter(oldValue.A + 1, oldValue.B + 1);
}
while (Interlocked.CompareExchange(ref counter, newValue, oldValue) != oldValue);
return newValue;
}
public static void IncrementCounters()
{
var result = Increment(ref Counter);
Console.WriteLine("{0},{1}",result.A,result.B);
}
}public class DualCounter{
public int A { get; }
public int B { get; }
public DualCounter(int a,int b)
{
A = a;
B = b;
}
}
无锁算法的优缺点
上面提到的无锁算法不一定比使用线程快。比如
每次都要New对象分配内存,这个取决于你的业务复杂度。
如果Interlocked.CompareExchange一直交换失败,会类似自旋锁一样大量占用CPU资源
简单汇总一下
优点:
缺点:
实现复杂:无锁算法的设计和实现相对复杂,需要深入理解底层的原子操作、内存模型和并发编程原理。错误的实现可能会导致数据不一致、死锁或者活锁等问题。
ABA 问题:这是无锁算法中常见的一个问题。例如在使用 CAS 操作时,一个内存位置的值从 A 变为 B,然后又变回 A,这可能会导致一些无锁算法误判。解决 ABA 问题通常需要额外的标记或者版本号机制来记录内存位置的变化历史。
内存顺序问题:在多核处理器环境下,由于处理器缓存和指令重排等因素,无锁算法需要考虑内存顺序问题,以确保不同线程对共享数据结构的操作顺序符合预期,避免出现数据不一致的情况。这通常需要使用内存屏障等技术来辅助解决。
转自https://www.cnblogs.com/lmy5215006/p/18585588
该文章在 2024/12/6 9:24:21 编辑过






 400 186 1886
400 186 1886


