尽管软件开发一直致力于追求高效、可读性强、易于维护的特性,但这些特性却像是一个不可能三角,相互交织,此消彼长。就像底层语言(如汇编和C语言)能够保持高效的运行性能,但在可读性和维护性方面却存在短板和劣势;而高级语言(如Java和Python)在可读性和可维护性方面表现出色,但在执行效率方面却存在不足。构建语言生态的优势,弥补其存在短板,始终是编程语言的一个演进方向。
不同编程语言,拥有不同的特性和规约,下面就以JAVA语言为例,细数那些开发过程中容易被人忽略,但必须掌握的知识点和实践技能。1999年,美国太空总署(NASA)的火星任务失败:在这次任务中,火星气候探测者号上的飞行系统软件使用公制单位牛顿计算推进器动力,而地面人员输入的方向校正量和推进器参数则使用英制单位磅力,导致探测器进入大气层的高度有误,最终瓦解碎裂。
这是由于国际标准(牛)和本土化(磅)的冲突导致的一起事故。由此引出了程序需要关注可维护性这个话题,由于软件生产往往需要多人协作,可维护性正是协作共识里的重要一环。关于这方面,让人最容易想到的就是命名和注释两个方面了,下面就展开来探讨一下。2.1 关于命名
按照阅读习惯,程序的变量命名法都需要克服单词间的空格问题,从而把不同单词串连起来,最终达到创造出一种易于阅读的新“单词”的效果。常见的命名方法有以下几种:- 蛇形命名法(snake case):又叫下划线命名法,使用下划线,单词小写,比如:my_system;
- 驼峰命名法(camel case):按照单词首字母区分大小写,又可细分为大驼峰命名法和小驼峰命名法,比如:MySystem,mySystem;
- 匈牙利命名法(HN case):属性+类型+描述,比如:nLength,g_cch, hwnd;
- 帕斯卡命名法(Pascal case):全部首字母大写,等同于大驼峰命名法,比如:MySystem;
- 脊柱命名法(spinal case):使用中划线,比如:my-system;
- 自由命名法(studly caps):大小写混杂,无简明规则,比如:mySYSTEM,MYSystem;
按照受众量与知名程度排名,驼峰命名法和蛇形命名法更受到大家的欢迎,毕竟它们在可读性,易写性等方面比较有优势。2.1.1 命名字典
建议研发同学将业内常见业务场景的命名熟记,当然,已经有人帮我们总结过了,这里不再做过多的说明。这里摘录如下,可供参考:管理类命名:Bootstrap,Starter,Processor,Manager,Holder,Factory,Provider,Registrar,Engine,Service,Task回调类命名:Handler,Callback,Trigger,Listener,Aware监控类命名:Metric,Estimator,Accumulator,Tracker内存管理类命名:Allocator,Chunk,Arena,Pool过滤检测类命名:Pipeline,Chain,Filter,Interceptor,Evaluator,Detector结构类命名:Cache,Buffer,Composite,Wrapper,Option, Param,Attribute,Tuple,Aggregator,Iterator,Batch,Limiter常见设计模式命名:Strategy,Adapter,Action,Command,Event,Delegate,Builder,Template,Proxy解析类命名:Converter,Resolver,Parser,Customizer,Formatter网络类命名:Packet,Encoder、Decoder、Codec,Request,ResponseCRUD命名:Controller,Service,Repository其他类命名:Mode,Type,Invoker,Invocation,Initializer,Future,Promise,selector,Reporter,Constants,Accessor,Generator2.1.2 命名实践
工程通用命名规则都有哪些呢?不同的语言可能会有不同的习惯,以Java语言的驼峰命名规范举例:- 变量名,方法名首字母小写,如果名称由多个单词组成,除首字母外的每个单词首字母都要大写;
- 自带混淆功能的变量名:String zhrmghg = "极致缩写型";
- 没有意义的万能变量名:String a,b,c="爱谁谁型";
- 长串拼音变量名:String HuaBuHua = "考古型";
- 各种符号混用:String $my_first_name_ = "打死记不住型";
- 大小写,数字,缩写混乱:String waitRPCResponse1 = "极易出错型";
除了标准的规范之外,在实际的开发过程中还会有一些困扰我们的实际案例。1. 在定义一个成员变量的时候,到底是使用包装类型还是使用基本数据类型呢?包装类和基本数据类型的默认值是不一样的,前者是null,后者依据不同类型其默认值也不一样。从数据严谨的角度来讲,包装类的null值能够表示额外信息,从而更加安全。比如可以规避基本类型的自动拆箱,导致的NPE风险以及业务逻辑处理异常风险。所以成员变量必须使用包装数据类型,基本数据类型则在局部变量的场景下使用。关于Java Bean中的getter/setter方法的定义其实是有明确的规定的,根据JavaBeans(TM) Specification规定,如果是普通的参数,命名为propertyName,需要通过以下方式定义其setter/getter:
public <PropertyType> get<PropertyName>();
public void set<PropertyName>(<PropertyType> p)
但是,布尔类型的变量propertyName则是另外一套命名原则的:
public boolean is<PropertyName>();
public void set<PropertyName>(boolean p)
- 一类是同一个jar包出现了多个不同的版本。应用选择了错误的版本导致jvm加载不到需要的类或者加载了错误版本的类;(借助maven管理工具相对容易解决)
- 另一类是不同的jar包出现了类路径相同的类,同样的类出现在不同的依赖jar里,由于jar加载的先后顺序导致了JVM加载了错误版本的类;(比较难以解决)
这里着重介绍第二种情况,这种情况容易出现在系统拆分重构时,将原有的项目进行了复制,然后删减,导致部分工具或者枚举类和原有的路径和命名都一样,当第三方调用方同时依赖了这两个系统时,就容易为以后的迭代埋下坑。要规避此类问题,一定要为系统起一个独一无二的package路径。
补充:如果依赖的都是第三方的库,存在着类冲突时,可以通过引入第三方库jarjar.jar,修改其中某个冲突jar文件的包名,以此来解决jar包冲突。5. 在变量命名的可读性和占用资源(内存,带宽)方面,如何去做权衡?可以通过对象序列化工具为突破口,以常见的Json(Jackson)序列化方式来举例:
public class SkuKey implements Serializable {
@JsonProperty(value = "sn")
@ApiModelProperty(name = "stationNo", value = " 门店编号", required = true)
private Long stationNo;
@JsonProperty(value = "si")
@ApiModelProperty(name = "skuId", value = " 商品编号", required = true)
private Long skuId;
// 省略get/set方法
}
2.2 关于注释
注释是程序员和阅读者之间交流的重要手段,是对代码的解释和说明,好的注释可以提高软件的可读性,减少维护软件的成本。2.2.1 好的注释
分层次:按照系统,包,类,方法,代码块,代码行等不同粒度,各有侧重点的进行注释说明。- 系统注释:通过README.md文件体现宏观的功能和架构实现;
- 包注释:通过package-info文件体现模块职责边界,另外该文件也支持声明友好类,包常量以及为标注在包上的注解(Annotation)提供便利;
- 类注释:主要体现功能职责,版本支持,作者归属,应用示例等相关信息;
- 方法注释:关注入参,出参,异常处理声明,使用场景举例等相关内容;
- 代码块和代码行注释:主要体现逻辑意图,闭坑警示,规划TODO,放大关注点等细节内容;
有规范:好的代码优于大量注释,这和我们常说的“约定大于配置”是相同的道理。借助swagger等三方库实现注解即接口文档,是一个不错的规范方式;2.2.2 坏的注释
为了能使注释准确清晰的表达出功能逻辑,注释的维护是有相当的维护成本的,所以注释并不是越多,越详细越好。下面就举一些坏的注释场景,辅助理解:- 冗余式:如果一个函数,读者能够很容易的就读出来代码要表达的意思,注释就是多余的;
- 错误式:如果注释地不清楚,甚至出现歧义,那还不如不写;
- 签名式:类似“add by liuhuiqing 2023-08-05”这种注释,容易过期失效而且不太可信(不能保证所有人每次都采用这种方式注释),其功能完全可以由git代码管理工具来实现;
- 长篇大论式:代码块里,夹杂了大篇幅的注释,不仅影响代码阅读,而且维护困难;
- 非本地注释:注释应该在离代码实现最近的地方,比如:被调用的方法注释就由方法本身来维护,调用方无需对方法做详细的说明;
- 注释掉的代码:无用的代码应该删除,而不是注释。历史记录交给git等代码管理工具来维护;
2.3 关于分层
系统分层设计的主要目的是通过分离关注点,来降低系统的复杂度,同时提高可复用性和降低维护成本。所以懂得分层的概念,很大程度上系统的可维护性就有了骨架。2.3.1 系统分层
在ISO((International Standardization Organization))于1981年制定网络通信七层模型(Open System Interconnection Reference Model,OSI/RM)之前,计算机网络中存在众多的体系结构,其中以IBM公司的SNA(系统网络体系结构)和DEC公司的DNA(DigitalNetworkArchitecture)数字网络体系结构最为著名。最早之前,各个厂家提出的不同标准都是以自家设备为基础的,用户在选择产品的时候就只能用同一家公司的,因为不同公司间大家的标准不一样,工作方式也可能不一样,结果就是不同厂商的网络产品间,可能会出现不兼容的情况。如果说同一家的公司的产品都能满足用户的需求的话,那就看哪家公司实力强点,实力强的,用户粘性高的,用户自然也不会说什么,问题是一家公司并不是对所有的产品都擅长。这就会导致厂商和用户都面临着痛苦的煎熬。类比一下当前手机充电接口协议(Micro USB接口、Type- c接口、Lightning接口),手头总是要备有各种充电线的场景,就能深刻理解标准的意义了。2.3.2 软件伸缩性
软件伸缩性指的是软件系统在面对负载压力时,能够保持原有性能并扩展以支持更多任务的能力。
伸缩性可以有两个方面,垂直伸缩性和水平伸缩性,垂直伸缩性是通过在同一个业务单元中增加资源来提高系统的吞吐量,比如增加服务器cpu的数量,增加服务器的内存等。水平伸缩性是通过增加多个业务单元资源,使得所有的业务单元逻辑上就像是一个单元一样。比如ejb分布式组件模型,微服务组件模型等都属于此种方式。
软件系统在设计时需要考虑如何进行有效的伸缩性设计,以确保在面对负载压力时能够提供足够的性能支持。系统分层从伸缩性角度看,更多的属于水平伸缩性的范畴。在J2EE系统开发当中,我们普遍采用了分层构架的方式,一般分为表现层,业务层和持久层。采用分层以后,因为层与层之间通信会引来额外的开销,所以给我们软件系统带来的就是每个业务处理开销会变大。既然采用分层会带来额外的开销,那么我们为什么还要进行分层呢?这是因为单纯依靠堆硬件资源的垂直伸缩方式来提高软件性能和吞吐是有上限的,而且随着系统规模的扩大,垂直伸缩的代价也将变得非常昂贵。当采用了分层以后,虽然层与层之间带来了通信开销,但是它有利于各层的水平伸缩性,并且各个层都可以进行独立的伸缩而不会影响到其它的层。也就是说当系统要应对更大的访问量的时候,我们可以通过增加多个业务单元资源来增加系统吞吐量。2.4 小结
本章内容主要从可读性和可维护性方面讲述了在开发过程中,要做好命名和注释的统一共识。除了共识之外,在设计层面也需要做好关注点的隔离,这包含系统职责的拆分,模块功能的划分,类能力的收敛,实体结构的关系都需要做好规划。下面就从程序的扩展性,维护性,安全性以及性能等几个重要质量指标,来学习那些经典的实践案例。3.1 类定义
3.1.1 常量定义
常量是一种固定值,不会在程序执行期间发生改变。你可以使用枚举(Enum)或类(Class)来定义常量。如果你需要定义一组相关的常量,那么使用枚举更为合适。枚举从安全性和可操作性(支持遍历和函数定义)上面拥有更大的优势。
public enum Color {
RED, GREEN, BLUE;
}
如果你只需要定义一个或少数几个只读的常量,那么使用类常量更为简洁和方便。
public class MyClass {
public static final int MAX_VALUE = 100;
}
3.1.2 工具类
工具类通常包含具有通用性的、某一非业务领域内的公共方法,不需要配套的成员变量,仅仅是作为工具方法被使用。因此,将其做成静态方法最合适,不需要实例化,能够获取到方法的定义并调用就行。工具类不实例化的原因是可以节省内存空间,因为工具类提供的是静态方法,通过类就能调用,不需要实例化工具类对象。
public abstract class ObjectHelper {
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
}
3.1.3 JavaBean
JavaBean的定义有两种常见实现方式:手动编写和自动生成。
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
使用lombok插件,通过注解方式来增强Java代码的编写,在编译期动态生成get和set方法。
import lombok.Data;
@NoArgsConstructor
@Data
@Accessors(chain = true)
public class Person {
private String name;
private int age;
}
3.1.4 不可变类
在某些场景下,类为了保证其功能和行为的稳定性和一致性,会被设计为不能被继承和重写的。定义方式就是在类上面添加final关键字,示例:
public final class String implements Serializable, Comparable<String>, CharSequence {
}
以下是一些不能被继承和重写的类,这在一些底层中间件中会有应用:
java.lang.String
java.lang.Math
java.lang.Boolean
java.lang.Character
java.util.Date
java.sql.Date
java.lang.System
java.lang.ClassLoader
3.1.5 匿名内部类
匿名内部类通常用于简化代码,它的定义和使用通常发生在同一处,它的使用场景如下:直接作为参数传递给方法或构造函数;
用于实现某个接口或抽象类的匿名实例;
public class Example {
public static void main(String[] args) {
// 创建一个匿名内部类
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Hello, World!");
}
};
// 调用匿名内部类的方法
runnable.run();
}
}
3.1.6 声明类
声明类是Java语言中的基本类型或接口,用于定义类的行为或特性,有的甚至只是个声明,没有具体的方法定义。- AutoCloseable:表示实现了该接口的类可以被自动关闭,通常用于资源管理。
- Comparable:表示实现了该接口的类可以与其他实现了该接口的对象进行比较。
- Callable:表示实现了该接口的类可以作为参数传递给线程池,并返回结果。
- Cloneable:表示实现了该接口的类可以被克隆。
- Runnable:表示实现了该接口的类可以作为线程运行。
- Serializable:表示实现了该接口的类可以被序列化和反序列化。
- interface:表示实现了该接口的类是一个接口,可以包含方法声明。
- Annotation:表示实现了该接口的类是一个注解,可以用于元数据描述。
3.1.7 Record 类
Record 类在 Java14 中就开始预览,一直到Java17 才正式发布。根据 JEP395 的描述,Record 类是不可变数据的载体,类似于当下广泛应用的各种 model,dto,vo 等 POJO 类,但 record 本身在构造之后不再可赋值。所有的 record 类都继承自 java.lang.Record。Record 类默认提供了全字段的构造器,属性的访问,还有 equals,hashcode,toString 方法,其作用和 lombok 插件非常类似。定义方式
/**
* 关键定义的类是不可变类
* 将所有成员变量通过参数的形式定义
* 默认会生成全部参数的构造方法
* @param name
* @param age
*/
public record Person(String name, int age) {
public Person{
if(name == null){
throw new IllegalArgumentException("提供紧凑的方式进行参数校验");
}
}
/**
* 定义的类中可以定义静态方法
* @param name
* @return
*/
public static Person of(String name) {
return new Person(name, 18);
}
}
使用方式
Person person = new Person("John", 30);
// Person person = Person.of("John");
String name = person.name();
int age = person.age();
通过Record 构建一个临时存储对象,将 Person 数组对象按照年龄排序。
public List<Person> sortPeopleByAge(List<Person> people) {
record Data(Person person, int age){};
return people.stream()
.map(person -> new Data(person, computAge(person)))
.sorted((d1, d2) -> Integer.compare(d2.age(), d1.age()))
.map(Data::person)
.collect(toList());
}
public int computAge(Person person) {
return person.age() - 1;
}
3.1.8 密封类
Java 17推出的新特性密封类(Sealed Classes),主要作用就是限制类的继承。我们知道之前对类继承功能的限制主要有两种:- package-private类,可以控制只能被同一个包下的类继承;
但很显然,这两种限制方式的力度都非常粗,而密封类正是对类继承的更细粒度的控制。
sealed class SealedClass permits SubClass1, SubClass2 {
}
class SubClass1 extends SealedClass {
}
class SubClass2 extends SealedClass {
}
3.2 方法定义
3.2.1 构造方法
构造方法是一种特殊的方法,用于创建和初始化对象。构造方法的名称必须与类名相同,并且没有返回类型。在创建对象时,可以通过使用 new 关键字来调用构造方法。
public class MyClass {
private int myInt;
private String myString;
// 构造方法
public MyClass(int myInt, String myString) {
this.myInt = myInt;
this.myString = myString;
}
}
3.2.2 方法重写
方法重写是指在子类中重新定义与父类中同名的方法。方法重写允许子类覆盖父类中的方法实现,以便根据子类的需要实现其自己的行为。
class Animal {
public void makeSound() {
System.out.println("Animal is making a sound");
}
}
class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("Meow");
}
}
public class Main {
public static void main(String[] args) {
Animal myCat = new Cat();
myCat.makeSound();
// 输出 "Meow"
}
}
3.2.3 方法重载
类中定义多个方法,它们具有相同的名称但参数列表不同。方法重载允许我们使用同一个方法名执行不同的操作,根据传递给方法的参数不同来执行不同的代码逻辑。
public class Calculator {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
public class Main {
public static void main(String[] args) {
Calculator calculator = new Calculator();
int result1 = calculator.add(2, 3);
double result2 = calculator.add(2.5, 3.5);
System.out.println(result1); // 输出 5
System.out.println(result2); // 输出 6.0
}
}
3.2.4 匿名方法
Java 8 引入了 Lambda 表达式,可以用来实现类似匿名方法的功能。Lambda 表达式是一种匿名函数,可以作为参数传递给方法,或者直接作为一个独立表达式使用。
public static void main(String args[]) {
List<String> names = Arrays.asList("hello", "world");
// 使用 Lambda 表达式作为参数传递给 forEach 方法
names.forEach((String name) -> System.out.println("Name: " + name));
// 使用 Lambda 表达式作为独立表达式使用
Predicate<String> nameLengthGreaterThan5 = (String name) -> name.length() > 5;
boolean isLongName = nameLengthGreaterThan5.test("John");
System.out.println("Is long name? " + isLongName);
}
3.3 对象定义
3.3.1 单例对象
单例对象是一种可以重复使用的对象,但只有一个实例。它有以下几个作用:- 控制资源的使用:通过线程同步来控制资源的并发访问。
- 作为通信媒介使用:也就是数据共享,它可以在不建立直接关联的条件下,让多个不相关的两个线程或者进程之间实现通信。
比如,使用枚举实现单例模式:
public enum Singleton {
INSTANCE;
public void someMethod() {
// ...其他代码...
}
}
3.3.2 不可变对象
Java中的不可变对象是指那些一旦被创建,其状态就不能被修改的对象。不可变对象是一种非常有用的对象,因为它们可以确保对象的状态在任何时候都是一致的,从而避免了因为修改对象状态而引发的问题。实现不可变对象有以下几种方式:- 将对象的状态存储在不可变对象中:String、Integer等就是内置的不可变对象类型;
- 将对象的状态存储在final变量中:final变量一旦被赋值就不能被修改;
- 将对象的所有属性都设为不可变对象:这样就可以确保整个对象都是不可变的;
一些容器类的操作也有对应的包装类实现容器对象的不可变,比如定义不可变数组对象:
Collections.unmodifiableList(new ArrayList<>());
当领域内的对象作为入参往外传递时,将其定义为不可变对象,这在保持数据一致性方面非常重要,否则对象属性变更的不可预测性,在进行问题定位时,将会非常麻烦。3.3.3 元组对象
元组(Tuple)是函数式编程语言中的常见概念,元组是一个不可变,并且能够以类型安全的形式保存多个不同类型的对象。它是一种非常有用的数据结构,可以让开发者在处理多个数据元素时更加方便和高效。但原生的Java标准库并没有提供元组的支持,需要我们自己或借助第三方类库来实现。二元组实现
public class Pair<A,B> {
public final A first;
public final B second;
public Pair(A a, B b) {
this.first = a;
this.second = b;
}
public A getFirst() {
return first;
}
public B getSecond() {
return second;
}
}
三元组实现
public class Triplet<A,B,C> extends Pair<A,B>{
public final C third;
public Triplet(A a, B b, C c) {
super(a, b);
this.third = c;
}
public C getThird() {
return third;
}
public static void main(String[] args) {
// 表示姓名,性别,年龄
Triplet<String,String,Integer> triplet = new Triplet("John","男",18);
// 获得姓名
String name = triplet.getFirst();
}
}
多元组实现
public class Tuple<E> {
private final E[] elements;
public Tuple(E... elements) {
this.elements = elements;
}
public E get(int index) {
return elements[index];
}
public int size() {
return elements.length;
}
public static void main(String[] args) {
// 表示姓名,性别,年龄
Tuple<String> tuple = new Tuple<>("John", "男", "18");
// 获得姓名
String name = tuple.get(0);
}
}
- 存储多个数据元素:Tuple可以存储多个不同类型的数据元素,这些元素可以是基本类型、对象类型、数组等;
- 简化代码:Tuple可以使代码更加简洁,减少重复代码的编写。通过Tuple,我们可以将多个变量打包成一个对象,从而减少了代码量;
- 提高代码可读性:Tuple可以提高代码的可读性。通过Tuple,我们可以将多个变量打包成一个对象,从而使代码更加易读;
- 支持函数返回多个值:Tuple可以支持函数返回多个值。在Java中,函数只能返回一个值,但是通过Tuple,我们可以将多个值打包成一个对象返回;
除了自定义之外,实现了元组概念的第三方类库有:Google Guava,Apache Commons Lang,JCTools,Vavr等。Google Guava库的Tuple提供了更多的功能,并且被广泛使用。比如,为了使元组的含义更加明确,Guava提供了命名元组(NamedTuple)的概念。通过给元组命名,可以更清晰地表示每个元素的意义。示例:
NamedTuple namedTuple = Tuples.named("person", "name", "age");
3.3.4 临时对象
临时对象是指在程序执行过程中临时需要,但生命周期较短的对象。这些对象通常只在使用过程中短暂存在,不需要长期存储或重复使用。- 尽量重用对象。由于系统不仅要花时间生成对象,以后可能还需花时间对这些对象进行垃圾回收和处理,因此,生成过多的对象将会给程序的性能带来很大的影响,重用对象的策略有缓存对象,也可以针对具体场景进行定向优化,比如使用StringBuffer代替字符串拼接的方式;
- 尽量使用局部变量。调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中,速度较快。其他变量,如静态变量、实例变量等,都在堆中创建,速度较慢;
- 分代收集。分代垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率;
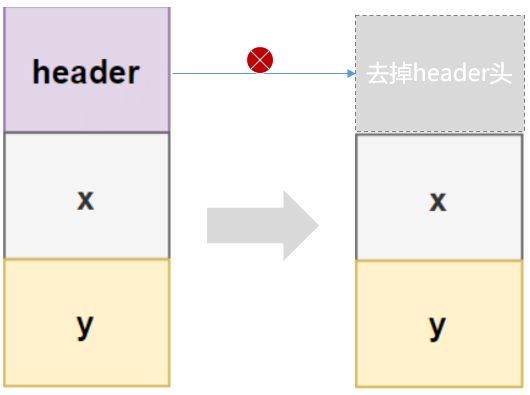
3.3.5 Valhalla
Java作为高级语言,和更为底层的C语言,汇编语言在性能方面一直存在着不小的差距。为了弥补这一差距,Valhalla 项目于 2014 年启动,目标是为基于 JVM 的语言带来更灵活的扁平化数据类型。我们都知道Java支持原生类型和引用类型两种。原生数据类型按值传递,赋值和函数传参都会把值给复制一份,复制之后两份之间就再无关联;引用类型无论什么情况传的都是指针,修改指针指向的内容会影响到所有的引用。而Valhalla又引入了值类型(value types),一种介于原生类型和引用类型之间的概念。由于应用程序中的大多数Java数据结构都是对象,因此我们可以将Java视为指针密集型语言。这种基于指针的对象实现用于启用对象标识,对象标识本身用于语言特性,如多态性、可变性和锁定。默认情况下,这些特性适用于每个对象,无论它们是否真的需要。这就是值类型(value types)发挥作用的地方。值类型(value types)的概念是表示纯数据聚合,这会删除常规对象的功能。因此,我们有纯数据,没有身份。当然,这意味着我们也失去了使用对象标识可以实现的功能。由于我们不再有对象标识,我们可以放弃指针,改变值类型的一般内存布局。让我们来比较一下对象引用和值类型内存布局。去掉了对象头信息,在64位操作系统中值类型节约了对象头16个字节的空间。同时,也意味着放弃对象唯一身份(Identity)和初始化安全性,之前的wait(),notify(),synchronized(obj),System.identityHashCode(obj)等关键字或方法都将失效,无法使用。Valhalla 在提高性能和减少泄漏的抽象方面将会显著提高:截止到2023年9月,Valhalla 项目仍在进行中,还没有正式版本的发布,这一创新项目值得期待的。本文总结了软件开发过程中经常用到的基础常识,分为基础篇和实践篇两个篇章,其中基础篇中着重讲述了类,方法,变量的命名规范以及代码注释好坏的评判标准。实践篇中从类,方法以及对象三个层面分析了常见的技术概念和落地实践,希望这些常识能够为读者带来一些思考和帮助。
该文章在 2023/12/12 17:37:40 编辑过






 400 186 1886
400 186 1886


