分布式哈希表 (DHT) 和 P2P 技术
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
1. 引言相信没有人没使用过 P2P 技术. BT 种子和磁力链接就是最常见的 P2P 技术, 使用 P2P 技术, 文件不再需要集中存储在一台服务器上, 而是分散再各个用户的节点上, 每个人都是服务的提供者, 也是服务的使用者. 这样的系统具有高可用性, 不会由于一两台机的宕机而导致整个服务不可用. 那么这样一个系统是怎样实现的, 如何做到去中心化(decentralization)和自我组织(self-organization)的呢? 这篇文章我们来讨论一下这个问题. 这篇文章先会介绍 P2P 网络的整体思路, 并引出 P2P 网络的主角 - 分布式哈希表(Distributed Hash Table, DHT); 接着会介绍两种分布式哈希表算法. 这些会让你对 P2P 技术有一个较为具体的了解. 2. P2P 网络的概述2.1 传统 CS 网络和 P2P 网络CS 架构即 Client-Server 架构, 由服务器和客户端组成: 服务器为服务的提供者, 客户端为服务的使用者. 我们如今使用的很多应用程序例如网盘, 视频应用, 网购平台等都是 CS 架构. 它的架构如下图所示:
当然服务器通常不是一个单点, 往往是一个集群; 但本质上是一样的. CS 架构的问题在于, 一旦服务器关闭, 例如宕机, 被 DDoS 攻击或者被查水表, 客户端就无法使用了, 服务也就失效了. 为了解决这个问题, 人们提出了 P2P 网络(Peer-to-peer Networking). 在 P2P 网络中, 不再由中心服务器提供服务, 不再有”服务器”的概念, 每个人即使服务的提供者也是服务的使用者 – i.e., 每个人都有可能是服务器. 我们常用的 BT 种子和磁力链接下载服务就是 P2P 架构. 人们对 P2P 系统作了如下定义:
一个 P2P 系统是每个节点都是平等, 自主的一个自我组织的系统, 目的是在避免中心服务的网络环境中共享使用分布式资源.
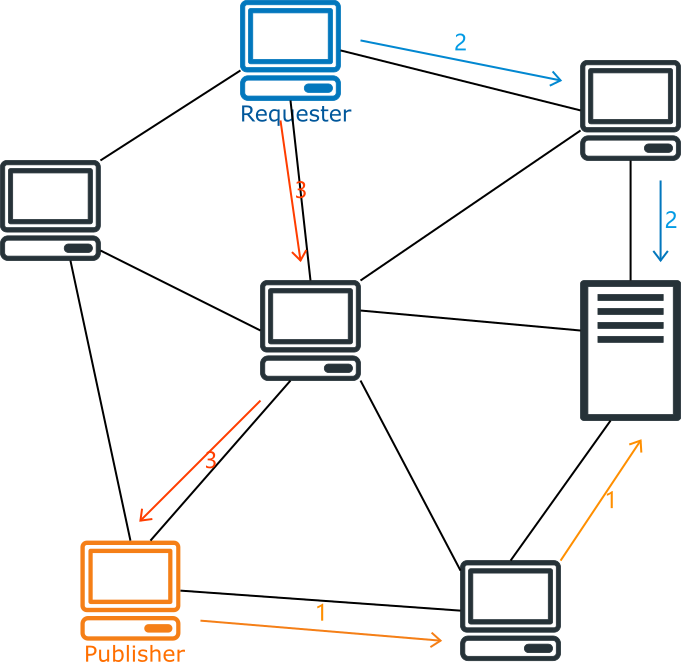
P2P 系统的架构如上图所示. 由于去掉了中心服务器, P2P 系统的稳定性就强很多: 少数几个个节点的失效几乎不会影响整个服务; 节点多为用户提供, 可以做到 “野火烧不尽, 春风吹又生”. 即使有人想恶意破坏, 也无法对整个系统造成有效打击. 2.2 朴素的 P2P 网络P2P 网络需要解决的一个最重要的问题就是, 如何知道用户请求的资源位于哪个节点上. 在第一代 P2P 网络中, 人们设置了一台中央服务器来管理资源所处的位置. 当一个用户想要发布资源, 他需要告诉中央服务器它发布的资源信息和自己的节点信息; 当其他用户请求资源的时候, 需要先请求中央服务器以获取资源发布者的节点信息, 再向资源发布者请求资源.
这种 P2P 网络的好处是效率高, 只需要请求一次中央服务器就可以发布或获取资源. 然而它的缺点也很明显: 中央服务器是这个网络系统最脆弱的地方, 它需要存储所有资源的信息, 处理所有节点的请求; 一旦中央服务器失效, 整个网络就无法使用. 早期的另外一种 P2P 网络采取了不同的策略, 它不设置中央服务器; 当用户请求资源时, 它会请求它所有的邻接节点, 邻接节点再依次请求各自的邻接节点, 并使用一些策略防止重复请求, 直到找到拥有资源的节点. 也就是说, 这是一种泛洪搜索(Flooding Search).
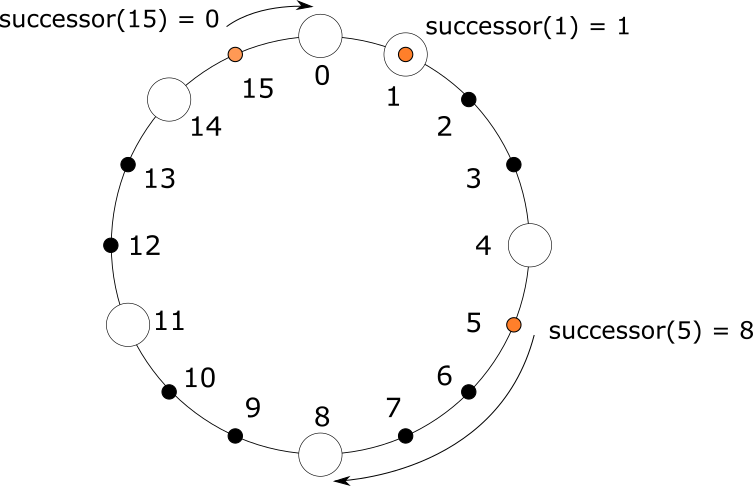
这种 P2P 网络去除了中央服务器, 它的稳定性就强多了. 然而它太慢了. 一次查找可能会产生大量的请求, 可能会有大量的节点卷入其中. 一旦整个系统中的的节点过多, 性能就会变得很差. 2.3 分布式哈希表为了解决这些问题, 分布式哈希表应运而生. 在一个有 个节点的分布式哈希表中, 每个节点仅需存储 个其他节点, 查找资源时仅需请求 个节点, 并且无需中央服务器, 是一个完全自组织的系统. 分布式哈希表有很多中实现算法, 第 3 节和第 4 节会详细介绍其中的两种. 这里我们先来看看它们共通的思想. 地址管理首先, 在分布式哈希表中, 每个节点和资源都有一个唯一标识, 通常是一个 160 位整数. 为方便起见, 我们称节点的唯一标识为 ID, 称资源的唯一标识为 Key. 我们可以把一个节点的 IP 地址用 SHA-1 算法哈希得到这个节点的 ID; 同样地, 把一个资源文件用 SHA-1 算法哈希就能得到这个资源的 Key 了. 定义好 ID 和 Key 之后, 就可以发布和存储资源了. 每个节点都会负责一段特定范围的 Key, 其规则取决于具体的算法. 例如, 在 Chord 算法中, 每个 Key 总是被第一个 ID 大于或等于它的节点负责. 在发布资源的的时候, 先通过哈希算法计算出资源文件的 Key, 然后联系负责这个 Key 的节点, 把资源存放在这个节点上. 当有人请求资源的时候, 就联系负责这个 Key 的节点, 把资源取回即可. 发布和请求资源有两种做法, 一种是直接把文件传输给负责的节点, 由它存储文件资源; 请求资源时再由这个节点将文件传输给请求者. 另一种做法是由发布者自己设法存储资源, 发布文件时把文件所在节点的地址传输给负责的节点, 负责的节点仅存储一个地址; 请求资源的时候会联系负责的节点获取资源文件的地址, 然后再取回资源. 这两种做法各有优劣. 前者的好处是资源的发布者不必在线, 请求者也能获取资源; 坏处是如果文件过大, 就会产生较大的传输和存储成本. 后者的好处是传输和存储成本都比较小, 但是资源的发布者, 或者说资源文件所在的节点必须一直在线. 路由算法上面我们简述了地址系统, 以及如何发布和取回资源. 但是现在还有一个大问题: 如何找到负责某个特定 Key 的节点呢? 这里就要用到路由算法了. 不同的分布式哈希表实现有不同的路由算法, 但它们的思路是一致的. 首先每个节点会由若干个其他节点的联系方式(IP 地址, 端口), 称之为路由表. 一般来说一个有着 个节点的分布式哈希表中, 一个节点的路由表的长度为 . 每个节点都会按照特定的规则构建路由表, 最终所有的节点会形成一张网络. 从一个节点发出的消息会根据特定的路由规则, 沿着网络逐步接近目标节点, 最终达到目标节点. 在有着 个节点的分布式哈希表中, 这个过程的转发次数通常为 次. 自我组织(self-organization)分布式哈希表中的节点都是由各个用户组成, 随时有用户加入, 离开或失效; 并且分布式哈希表没有中央服务器, 也就是说着这个系统完全没有管理者. 这意味着分配地址, 构建路由表, 节点加入, 节点离开, 排除失效节点等操作都要靠自我组织策略实现. 要发布或获取资源, 首先要有节点加入. 一个节点加入通常有以下几步. 首先, 一个新节点需要通过一些外部机制联系分布式哈希表中的任意一个已有节点; 接着新节点通过请求这个已有节点构造出自己的路由表, 并且更新其他需要与其建立连接的节点的路由表; 最后这个节点还需要取回它所负责的资源. 此外我们必须认为节点的失效是一件经常发生的事, 必须能够正确处理它们. 例如, 在路由的过程中遇到失效的节点, 会有能够替代它的其他节点来完成路由操作; 会定期地检查路由表中的节点是否有效; 将资源重复存储在多个节点上以对抗节点失效等. 另外分布式哈希表中的节点都是自愿加入的, 也可以自愿离开. 节点离开的处理与节点失效类似, 不过还可以做一些更多的操作, 比如说立即更新其他节点的路由表, 将自己的资源转储到其他节点等. 3. Chord 算法上一节简单介绍了 P2P 网络和分布式哈希表, 现在我们来讨论它的一个具体实现. 分布式哈希表有很多中实现, Ion Stoica 和 Robert Morris 等人在 2001 年的一篇论文中提出了 Chord 算法, 原论文已在文章末尾的参考资料中给出. Chord 算法比较简洁, 也很漂亮, 这里我们先介绍它. 3.1 地址管理正如 2.3 节所述, Chord 使用一个 m 位整数作为节点和资源的唯一标识. 也就是说标识的取值范围为 至 的整数. Chord 把所有的 ID 排列成一个环, 从小到大顺时针排列, 首尾相连. 为了方便起见, 我们称每个 ID 都先于它逆时针方向的 ID, 后于它顺时针方向的 ID. 每个节点都能在这个环中找到自己的位置; 而对于 Key 值为 k 的资源来说, 它总是会被第一个 ID 先于或等于 k 的节点负责. 我们把负责 k 的节点称为 k 的后继, 记作 . 例如, 如下图所示, 在一个 m = 4 的 Chord 环中, 有 ID 分别为 0, 1, 4, 8, 11, 14 的六个节点. Key 为 1 的资源被 ID 为 1 的节点负责, Key 为 5 的资源被 ID 为 8 的节点负责, Key 为 15 的资源被 ID 为 0 的节点负责. 也就是有 , , .
3.2 路由算法在 Chord 算法中, 每个节点都保存一个长度为 m 的路由表, 存储至多 m 个其他节点的信息, 这些信息能让我们联系到这些节点. 假设一个节点的 ID 为 n(以下简称节点 n), 那么它的路由表中第 i 个节点应为第一个 ID 先于或等于 的节点, 即 , 这里 . 我们把 n 的路由表中的第 i 个节点记作 . 显然, 路由表中的第一个节点为顺时针方向紧挨着 n 的节点, 我们通常称它为节点 n 的后继节点, 记作 .
有了这个路由表, 我们就可以快速地寻址了. 假设一个节点 n 需要寻找 Key 值为 k 的资源所在的节点, 即寻找 , 它首先判断 k 是否落在区间 内; 如果是, 则说明这个 Key 由它的后继负责. 否则 n 从后向前遍历自己的路由表, 直到找到一个 ID 后于 k 的节点, 然后把 k 传递给这个节点由它执行上述查找工作, 直到找到为止.
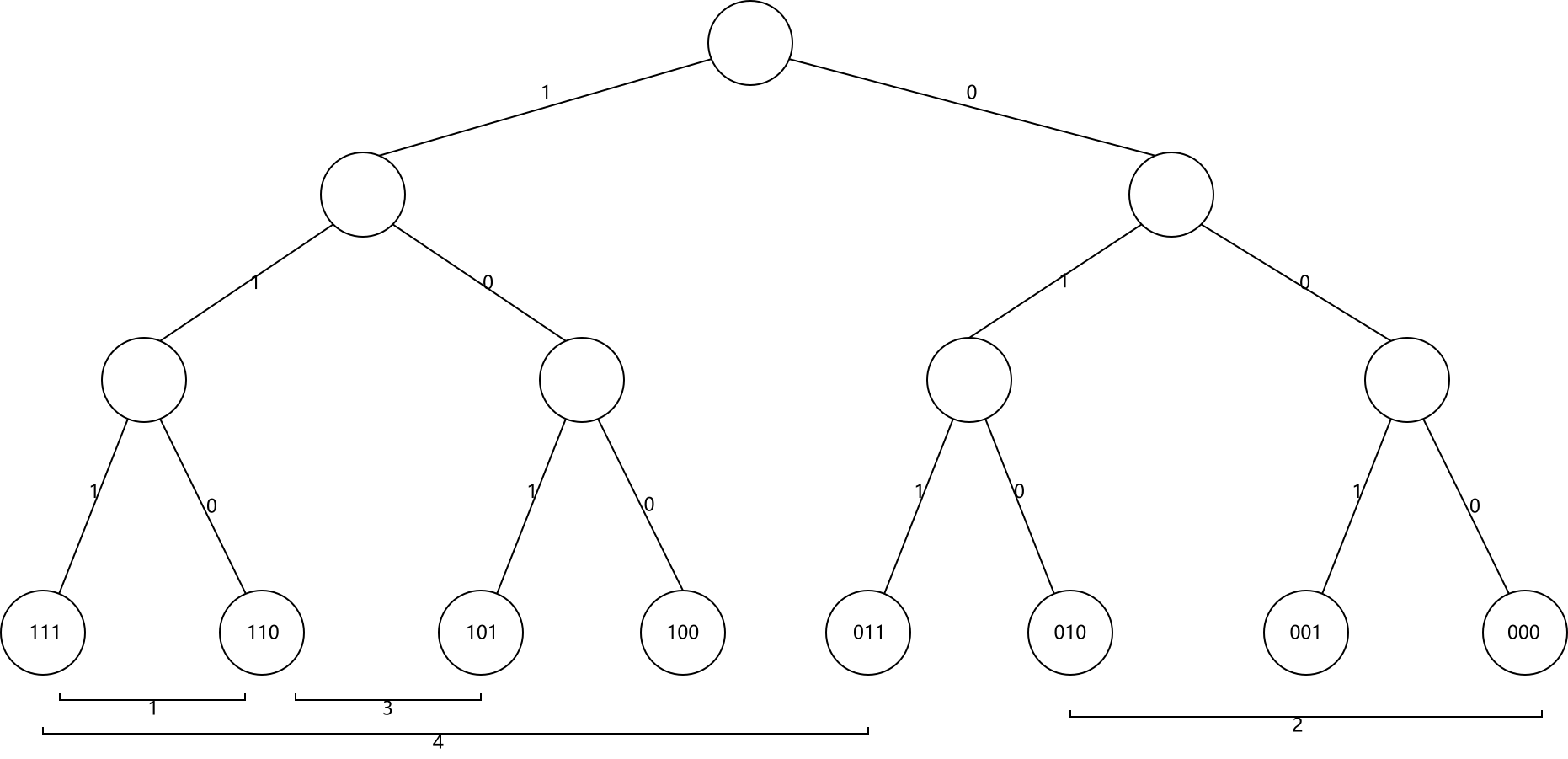
上图展示了从节点 4 寻找节点 1 的过程. 节点 4 的路由表中的节点分别为 8, 11, 14. 它首先会从后向前找到路由表中第一个后于 1 的节点为 14, 然后就请求 14 帮忙寻找 1. 节点 14 的路由表分别为 0, 4, 8; 同样地, 14 就会请求节点 0 帮忙寻找 1. 最终节点 0 找到它的后继即为节点 1. 可以看到, 整个查找过程是逐步逼近目标目标节点的. 离目标节点越远, 跳跃的距离就越长; 离目标节点越近, 跳跃的距离就越短, 越精确. 若整个系统有 N 个节点, 查找进行的跳跃次数就为 . 3.3 自我组织节点加入一个节点要想加入 Chord 并不难. 上一节说了, Chord 系统中的任意一个节点都能对任意 Key k 找到它的后继 . 首先, 新节点 使用一些算法生成自己的 ID, 然后它需要联系系统中的任意一个节点 , 让他帮忙寻找 . 显然, 即是 n 的后继节点, 同时也是它路由表中的第一个节点. 接下来它再请求 帮忙分别寻找 , , 等等, 直到构建完自己的路由表. 构建完自己的路由表后, n 基本上算是加入 Chord 了. 不过还不够, 因为这时其他的节点还不知晓它的存在. n 加入后, 有些节点的路由表中本该指向 n 的指针却仍指向 n 的后继. 这个时候就需要提醒这些节点更新路由表. 哪些节点需要更新路由表呢? 我们只需把操作反过来: 对所有的 , 找到第一个后于 的节点. 这与寻找后继相同, 就不再赘述了. 最后, 新节点 n 还需要取回它负责的所有资源. n 只需联系它的后继取回它后继所拥有的所有 Key 后于或等于 n 的资源即可. 处理并发问题考虑多个节点同时加入 Chord. 如果使用上述方法, 就有可能导致路由表不准确. 为此, 我们不能在新节点加入的时候一次性更新所有节点的路由表. Chord 算法非常重要的一点就是保证每个节点的后继节点都是准确的. 为了保证这一点, 我们希望每个节点都能和它的后继节点双向通信, 彼此检查. 因此我们给每个节点添加一个属性 指向它的前序节点. 然后, 我们让每个节点定期执行一个操作, 称之为 . 在 操作中, 每个节点 都会向自己的后继节点 请求获取 的前序节点 . 然后 会检查 是否更适合当它的后继, 如果是, 就它自己的后继更新为 . 同时 告诉自己的后继 自己的存在, 又会检查 是否更适合当它的前序, 如果是, 就把自己的前序更新为 . 这个操作足够简单, 又能够保证 Chord 环的准确性. 当新节点 加入 Chord 时, 首先联系已有节点 获取到 . 除了设置好自己的后继之外, 什么都不会做; 此时 还没有加入 Chord 环. 这要等到 执行之后: 当 执行 时, 会通知它的后继更新前序为 ; 当 真正的前序 执行 时会把自己的后继修正为 , 并通知 设置前序为 . 这样 就加入到 Chord 环中了. 这样的操作在多个节点同时加入时也是正确有效的. 此外每个节点 还会定期修复自己的路由表, 以确保能指向正确的节点. 具体的做法是随机选取路由表中的第 个节点, 查找并更新 为 . 由于 的后继节点始终是正确的, 所以这个查找操作始终是有效的. 节点失效与离开一旦有节点失效, 势必会造成某个节点的后继节点失效. 而后继节点的准确性对 Chord 来说至关重要, 它的失效意味着 Chord 环断裂, 可能导致查找失效, 操作无法进行. 为了解决这个问题, 一个节点通常会维护多个后继节点, 形成一个后继列表, 它的长度通常是 m. 这样的话, 当一个节点的后继节点失效后, 它会在后继列表中寻找下一个替代的节点. 此外一个节点的失效意味着这个节点上资源的丢失, 因此一个资源除了存储在负责它的节点 n 上之外, 还会被重复地存储在 n 的若干个后继节点上. 节点离开的处理与节点失效相似, 不同的是节点离开时可以做一些额外的操作, 例如通知它周围的节点立即执行 操作, 把资源转移到它的后继, 等等. 4. Kademlia 算法Petar Maymounkov 和 David Mazières 在 2002 年的一篇论文中提出了 Kademlia 算法, 原论文已在文章末尾的参考资料中给出. 相比与 Chord 算法, Kademlia 算法容错度更高, 效率也高于 Chord, 也更巧妙合理. 4.1 地址管理Kademlia 同样使用 m 位整数作为节点和资源的唯一标识. 与 Chord 中的 “区间负责制” 不同, Kademlia 中的资源都是被离它最近的节点负责. 出于容错考虑, 每个资源通常都被距离它最近的 k 个节点负责, 这里 k 是一个常量, 通常取 k 使得在系统中任意 k 个节点都不太可能在一小时之内同时失效, 比如取 k = 20. 有趣的是, 这里的 “距离” 并不是数值之差, 而是通过异或运算得出的. 在 Kademlia 中, 每个节点都可以看作一颗高度为 m + 1 的二叉树上的叶子节点. 把 ID 二进制展开, 从最高位开始, 自根节点逢 1 向左逢 0 向右, 直到抵达叶子节点. 如下图所示.
Kademlia 的巧妙之处就是定义两个 ID 和 之间的距离为 . 异或运算的特点是异为真同为假, 如果两个 ID 高位相异低位相同, 它们异或的结果就大; 如果它们高位相同低位相异, 异或的结果就小. 这与二叉树中叶子的位置分布是一致的: 如果两个节点共有的祖先节点少(高位相异), 它们的距离就远; 反之, 如果共有的祖先节点多(高位相同), 它们的距离就近. 上图标注了一些节点之间的距离, 大家可以感受一下. 异或运算的另一个重要性质是, 异或的逆运算仍是异或. 即如果有 则 . 这就意味着对于每个节点, 给的一个距离 , 至多有一个与其距离为 节点. 这样一来 Kademlia 的拓扑结构是单向的(unidirectional). 单向性确保不管查找从哪个节点开始, 同一 Key 的所有查找都会沿着同一路径收敛. 4.2 路由算法对于任意一个给定节点, 我们将二叉树从根节点开始不断向下分成一系列不包含该节点的子树. 最高的子树由不包含该节点的二叉树的一半组成, 下一个子树又由不包含该节点的剩余树的一半组成, 以此类推. 如果这个二叉树的高度为 m + 1, 我们最终会得到 m 个子树. 接着在每个子树中任取 k 个节点, 形成 m 个 k 桶(k-bucket), 这 m 个 k 桶就是 Kademlia 节点的路由表. 我们定义最小子树中取得的节点为第 0 个 k 桶, 次小的子树中取得的节点为第 1 个 k 桶, 以此类推. 不难看出, 对于每个 , 第 个 k 桶中节点与当前节点的距离总是在区间 之内. 下图展示了 m = 3, k = 2 时节点 101 的 k 桶.
Kademlia 中每个节点都有一个基础操作, 称为 有了 在接下来的递归过程中, 初始节点每次都在上一次请求后返回的节点中取 个最近的, 并且未被请求过的节点, 然后请求它们为 Key 执行 Kademlia 的大多数操作都基于节点查找. 发布资源时, 只需为资源的 Key 执行节点查找, 获取 k 个距离资源最近的节点, 把资源存储在这些节点上. 获取资源也类似, 也只需为目标资源的 Key 执行节点查找, 不同的是一旦遇到拥有目标资源的节点就停止查找. 此外, 一旦一个节点查找成功, 它就会把资源缓存在离自己最近的节点上. 因为 Kademlia 的拓扑结构是单向的, 其他离目标资源比自己远的节点在查找时就很可能会经由缓存的节点, 这样就能提前终止查找, 提高了查找效率. 4.3 自我组织k 桶的维护所有的 k 桶都遵循最近最少使用(Least Recently Used, LRU)淘汰法. 最近最少活跃的节点排在 k 桶的头部, 最近最多活跃的节点排在 k 桶尾部. 当一个 Kademlia 节点接收到任何来自其他节点的消息(请求或响应)的时候, 都会尝试更新相应的 k 桶. 如果这个节点在接收者对应的 k 桶中, 接收者就会把它移动到 k 桶的尾部. 如果这个节点不在相应的 k 桶中, 并且 k 桶的节点小于 k 个, 那么接收者就会直接把这个节点插入到这个 k 桶的尾部. 如果相应的 k 桶是满的, 接收者就会尝试 ping 这个 k 桶中最近最少活跃的节点. 如果最近最少活跃的节点失效了, 那么就移除它并且将新节点插入到 k 桶的尾部; 否则就把最近最少活跃的节点移动到 k 桶尾部, 并丢弃新节点. 通过这个机制就能在的通信的同时刷新 k 桶. 为了防止某些范围的 Key 不易被查找的情况, 每个节点都会手动刷新在上一小时未执行查找的 k 桶. 做法是在这个 k 桶中随机选一个 Key 执行节点查找. 节点加入一个新节点 要想加入 Kademlia, 它首先使用一些算法生成自己的 ID, 然后它需要通过一些外部手段获取到系统中的任意一个节点 , 把 加入到合适的 k 桶中. 然后对自己的 ID 执行一次节点查找. 根据上述的 k 桶维护机制, 在查找的过程中新节点 就能自动构建好自己的 k 桶, 同时把自己插入到其他合适节点的 k 桶中, 而无需其他操作. 节点加入时除了构建 k 桶之外, 还应该取回这个节点应负责的资源. Kademlia 的做法是每隔一段时间(例如一个小时), 所有的节点都对其拥有的资源执行一次发布操作; 此外每隔一段时间(例如24小时)节点就会丢弃这段时间内未收到发布消息的资源. 这样新节点就能收到自己须负责的资源, 同时资源总能保持被 k 个距离它最近的节点负责. 如果每个小时所有节点都重发它们所拥有的资源, 就有些浪费了. 为了优化这一点, 当一个节点收到一个资源的发布消息, 它就不会在下一个小时重发它. 因为当一个节点收到一个资源的发布消息, 它就可以认为有 k - 1 个其他节点也收到了这个资源的发布消息. 只要节点重发资源的节奏不一致, 这就能保证每个资源都始终只有一个节点在重发. 节点失效和离开有了上述 k 桶维护和资源重发机制, 我们不需要为节点的失效和离开做任何其它的工作. 这也是 Kademlia 算法的巧妙之处, 它的容错性要高于其他分布式哈希表算法. 5. 总结这篇文章介绍了 P2P 技术和分布式哈希表, 以及两种分布式哈希表算法, 基本介绍了它们的原理和实现机制. 文本也是笔者对这两篇论文学习的总结, 限于篇幅和笔者的精力, 对于其中的一些实现细节, 策略背后的理论和实验支撑, 算法的证明等未予阐述. 建议想要深入学习的同学阅读参考资料中的内容. 搭建 P2P 架构是一项很有挑战性的工作, 笔者认为即使不从事 P2P 开发, 了解和学习 P2P 技术对于服务器架构方面也是很有帮助的. 这篇文章应该是笔者目前写过字数最多的文章了, 写作过程很不容易, 一方面是参考资料只有英文, 另一方面要想把各种算法和机制阐述明白需要不断地斟酌词句. 最后希望这篇文章能对大家有所帮助. 参考资料 - Peer-to-Peer Systems and Applications - Chord: A scalable peer-to-peer lookup service for internet applications - Kademlia: A Peer-to-Peer Information System Based on the XOR Metric 该文章在 2023/8/31 18:56:41 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886